Perbezaan antara pembelajaran mesin yang diselia dan tidak diselia

Perbezaan utama - diselia vs Tanpa pengawasan Pembelajaran Mesin
Pembelajaran yang diselia dan pembelajaran tanpa pengawasan adalah dua konsep teras pembelajaran mesin. Pembelajaran yang diselia adalah tugas pembelajaran mesin untuk mempelajari fungsi yang memaparkan input ke output berdasarkan contoh pasangan input-output. Pembelajaran yang tidak diselia adalah tugas pembelajaran mesin untuk menyimpulkan fungsi untuk menggambarkan struktur tersembunyi dari data yang tidak dilabel. The Perbezaan utama antara pembelajaran mesin yang diawasi dan tidak diselia adalah bahawa Penggunaan pembelajaran yang diselia menggunakan data berlabel sementara pembelajaran tanpa pengawasan menggunakan data yang tidak berlabel.
Pembelajaran Mesin adalah bidang dalam sains komputer yang memberikan keupayaan untuk sistem komputer untuk belajar dari data tanpa diprogramkan secara eksplisit. Ia membolehkan untuk menganalisis data dan meramalkan corak di dalamnya. Terdapat banyak aplikasi pembelajaran mesin. Sebilangan daripada mereka adalah pengiktirafan muka, pengiktirafan isyarat dan pengiktirafan pertuturan. Terdapat pelbagai algoritma yang berkaitan dengan pembelajaran mesin. Sebilangan daripada mereka adalah regresi, klasifikasi dan clustering. Bahasa pengaturcaraan yang paling biasa untuk membangunkan aplikasi berasaskan pembelajaran mesin adalah r dan python. Bahasa lain seperti Java, C ++ dan MATLAB juga boleh digunakan.
Kandungan
1. Gambaran Keseluruhan dan Perbezaan Utama
2. Apa yang diawasi pembelajaran
3. Apa itu pembelajaran tanpa pengawasan
4. Persamaan antara pembelajaran mesin yang diawasi dan tidak diselia
5. Perbandingan sampingan - Penyelia vs pembelajaran mesin tanpa pengawasan dalam bentuk jadual
6. Ringkasan
Apa yang diawasi pembelajaran?
Dalam sistem berasaskan pembelajaran mesin, model ini berfungsi mengikut algoritma. Dalam pembelajaran yang diawasi, model ini diselia. Pertama, diperlukan untuk melatih model. Dengan pengetahuan yang diperoleh, ia dapat meramalkan jawapan untuk keadaan masa depan. Model ini dilatih menggunakan dataset berlabel. Apabila keluar dari data sampel diberikan kepada sistem, ia dapat meramalkan hasilnya. Berikut adalah ekstrak kecil dari dataset iris yang popular.
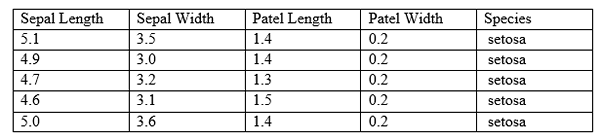
Menurut jadual di atas, panjang sepal, lebar sepal, panjang patel, lebar patel dan spesies dipanggil atribut. Lajur dikenali sebagai ciri. Satu baris mempunyai data untuk semua atribut. Oleh itu, satu baris dipanggil pemerhatian. Data boleh menjadi berangka atau kategori. Model diberi pemerhatian dengan nama spesies yang sepadan sebagai input. Apabila pemerhatian baru diberikan, model harus meramalkan jenis spesies yang dimilikinya.
Dalam pembelajaran yang diawasi, terdapat algoritma untuk klasifikasi dan regresi. Klasifikasi adalah proses mengklasifikasikan data berlabel. Model ini mencipta sempadan yang memisahkan kategori data. Apabila data baru diberikan kepada model, ia boleh mengkategorikan berdasarkan di mana titik ada. Jiran K-terdekat (KNN) adalah model klasifikasi. Bergantung pada nilai K, kategori diputuskan. Sebagai contoh, apabila k ialah 5, jika titik data tertentu hampir lapan titik data dalam kategori A dan enam titik data dalam Kategori B, maka titik data akan diklasifikasikan sebagai A.
Regresi adalah proses meramalkan trend data sebelumnya untuk meramalkan hasil data baru. Dalam regresi, output boleh terdiri daripada satu atau lebih pembolehubah berterusan. Ramalan dilakukan menggunakan garis yang merangkumi kebanyakan titik data. Model regresi yang paling mudah adalah regresi linear. Ia pantas dan tidak memerlukan parameter penalaan seperti di KNN. Sekiranya data menunjukkan trend parabola, maka model regresi linear tidak sesuai.
Ini adalah beberapa contoh algoritma pembelajaran yang diselia. Umumnya, hasil yang dihasilkan daripada kaedah pembelajaran yang diselia adalah lebih tepat dan boleh dipercayai kerana data input diketahui dan dilabelkan. Oleh itu, mesin hanya perlu menganalisis corak tersembunyi.
Apa itu pembelajaran tanpa pengawasan?
Dalam pembelajaran yang tidak diselia, model tidak diselia. Model ini berfungsi sendiri, untuk meramalkan hasilnya. Ia menggunakan algoritma pembelajaran mesin untuk membuat kesimpulan mengenai data yang tidak berlabel. Umumnya, algoritma pembelajaran yang tidak diselia lebih sukar daripada algoritma pembelajaran yang diawasi kerana terdapat sedikit maklumat. Clustering adalah jenis pembelajaran yang tidak diselia. Ia boleh digunakan untuk mengumpulkan data yang tidak diketahui menggunakan algoritma. K-mean dan clustering berasaskan kepadatan adalah dua algoritma clustering.
Algoritma K-Mean, tempat k centroid secara rawak untuk setiap kelompok. Kemudian setiap titik data diberikan kepada centroid terdekat. Jarak Euclidean digunakan untuk mengira jarak dari titik data ke centroid. Titik data diklasifikasikan ke dalam kumpulan. Kedudukan untuk c centroid dikira lagi. Kedudukan centroid baru ditentukan oleh min bagi semua mata dalam kumpulan. Sekali lagi setiap titik data diberikan kepada centroid terdekat. Proses ini berulang sehingga centroid tidak lagi berubah. K-Mean adalah algoritma kluster yang cepat, tetapi tidak ada inisialisasi titik kluster yang ditentukan. Juga, terdapat variasi model clustering yang tinggi berdasarkan permulaan titik kluster.
Algoritma kluster lain adalah Clustering berasaskan kepadatan. Ia juga dikenali sebagai aplikasi kluster spatial berasaskan ketumpatan dengan bunyi bising. Ia berfungsi dengan menentukan kelompok sebagai set maksimum titik ketumpatan yang disambungkan. Mereka adalah dua parameter yang digunakan untuk kluster berasaskan ketumpatan. Mereka adalah ɛ (Epsilon) dan mata minimum. Ɛ adalah jejari maksimum kejiranan. Titik minimum adalah bilangan minimum mata di kejiranan ɛ untuk menentukan kelompok. Ini adalah beberapa contoh clustering yang jatuh ke dalam pembelajaran yang tidak diselia.
Umumnya, hasil yang dihasilkan dari algoritma pembelajaran yang tidak diselia tidak banyak tepat dan boleh dipercayai kerana mesin harus menentukan dan melabelkan data input sebelum menentukan corak dan fungsi tersembunyi.
Apakah persamaan antara pembelajaran mesin yang diselia dan tidak diselia?
- Kedua -dua pembelajaran yang diselia dan tidak diselia adalah jenis pembelajaran mesin.
Apakah perbezaan antara pembelajaran mesin yang diselia dan tidak diselia?
Penyelia vs pembelajaran mesin tanpa pengawasan | |
| Pembelajaran yang diselia adalah tugas pembelajaran mesin untuk mempelajari fungsi yang memetakan input ke output berdasarkan contoh pasangan input-output. | Pembelajaran yang tidak diselia adalah tugas pembelajaran mesin untuk menyimpulkan fungsi untuk menggambarkan struktur tersembunyi dari data yang tidak berlabel. |
| Fungsi utama | |
| Dalam pembelajaran yang diawasi, model meramalkan hasilnya berdasarkan data input berlabel. | Dalam pembelajaran yang tidak diselia, model itu meramalkan hasilnya tanpa data berlabel dengan mengenal pasti coraknya sendiri. |
| Ketepatan hasil | |
| Keputusan yang dihasilkan daripada kaedah pembelajaran yang diselia adalah lebih tepat dan boleh dipercayai. | Hasil yang dihasilkan dari kaedah pembelajaran yang tidak diselia tidak tepat dan boleh dipercayai. |
| Algoritma Utama | |
| Terdapat algoritma untuk regresi dan klasifikasi dalam pembelajaran yang diawasi. | Terdapat algoritma untuk clustering dalam pembelajaran tanpa pengawasan. |
Ringkasan -diselia vs Tanpa pengawasan Pembelajaran Mesin
Pembelajaran yang diselia dan pembelajaran tanpa pengawasan adalah dua jenis pembelajaran mesin. Pembelajaran yang diselia adalah tugas pembelajaran mesin untuk mempelajari fungsi yang memetakan input ke output berdasarkan contoh pasangan input-output. Pembelajaran yang tidak diselia adalah tugas pembelajaran mesin untuk menyimpulkan fungsi untuk menggambarkan struktur tersembunyi dari data yang tidak berlabel. Perbezaan antara pembelajaran mesin yang diselia dan tidak diselia adalah bahawa pembelajaran yang diselia menggunakan data berlabel semasa bersandar tanpa pengawasan menggunakan data yang tidak berlabel.
Rujukan:
1.Thebigdatauniversity. Pembelajaran Mesin - Penyelia vs pembelajaran tanpa pengawasan, kelas kognitif, 13 mar. 2017. Terdapat di sini
2."Pembelajaran tanpa pengawasan."Wikipedia, Yayasan Wikimedia, 20 Mar. 2018. Terdapat di sini
3."Pembelajaran yang diawasi."Wikipedia, Yayasan Wikimedia, 15 Mar. 2018. Terdapat di sini
Ihsan gambar:
1.'2729781' oleh GDJ (Domain Awam) melalui Pixabay